
Map
1 | public interface Map<K,V> |
框架:
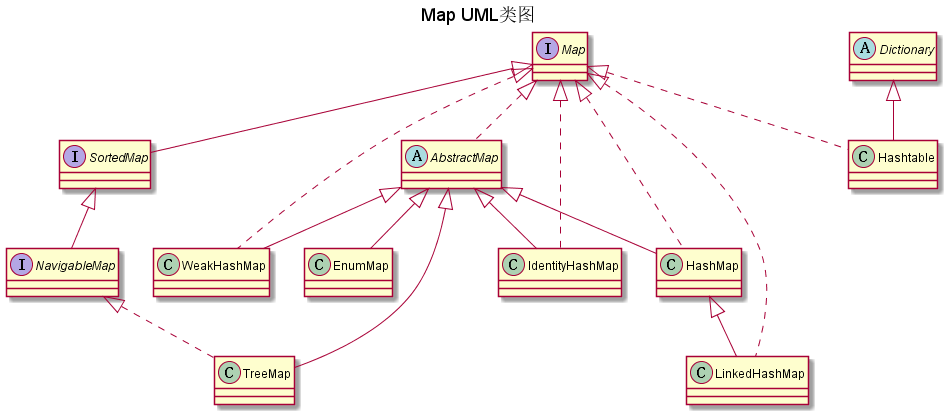
AbstractMap
1 | public abstract class AbstractMap<K,V> implements Map<K,V> |
- 唯一抽象方法
1 | public abstract Set<Entry<K,V>> entrySet(); |
- 不可变,需要重写put()方法
1 | public V put(K key, V value) { |
- 成员变量
1 | transient volatile Set<K> keySet; //1.8 去除volatile |
- hashCode() 值为每个entry的hash和
- equals()
同一个对象?—> 是否Map?—> 长度一样?—> 遍历每个entry的key和value
- 内部类
SimpleEntry 与 SimpleImmutableEntry唯一的区别就是支持 setValue() 操作。
HashMap
1 | public class HashMap<K,V> extends AbstractMap<K,V> |
数据结构
- 允许空键,空值
- 负载因子 0.75
- 初始长度 1 << 4
- 数组最大长度 1 << 30
- 非线程安全 使用Collections.synchronizedMap()包装
- fail-fast机制。iterator迭代更改map结构会抛出 ConcurrentModificationException,通过iterator.remove()删除元素
- jdk8 使用红黑树来优化元素均匀分布
TREEIFY_THRESHOLD = 8一个桶的树化阈值,当桶中元素个数超过这个值时,需要使用红黑树节点替换链表节点UNTREEIFY_THRESHOLD = 6一个树的链表还原阈值,桶中元素个数小于这个值,就会把树形的桶元素 还原(切分)为链表结构int MIN_TREEIFY_CAPACITY = 64哈希表的最小树形化容量, 这个值不能小于 4 * TREEIFY_THRESHOLD
- 链表节点:
1 | static class Node<K,V> implements Map.Entry<K,V> { |
- TreeNode节点
1 | static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { |
源码分析
hash计算
1 | static final int hash(Object key) { |
当hash数组的长度为 2^n 时, table.length -1 后, 最低的 n-1 位全部为1, 说明hash值存放的位置由hash值的低 n-1 位决定. 而HashMap计算hash值时, 同时兼顾了hash值的高位与低位.
get方法
1 | public V get(Object key) { |
步骤:
- (length - 1) & hash 做hash找出bucket位置
- 首节点hash和key与所找的相同,返回首节点
- equals() 比较key
- jdk8 会先做treeNode 节点类型判断
put方法
1 | public V put(K key, V value) { |
JDK7中先扩容再插入,插入时插入链表首节点;而JDK8先插入值再扩容,插入时插在链表尾部
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
步骤:
- 空表进行resize()
- hash 对应位置没有发生碰撞,直接插入
- 发生碰撞,链表节点将遍历节点,插入最后,超过TREEIFY_THRESHOLD,转为树形结构
- TreeNode, 红黑树找到父节点,进行插入
- 如果节点已经存在,进行替换
- 超过负载因子,进行resize()
冲突链表改为红黑树
1 | //该方法的主要作用是将冲突链表改为红黑树 |
resize方法
1 | final Node<K,V>[] resize() { |
扩容原理:翻倍扩容,节点要么在原来位置,要么两倍偏移
jdk7 同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到Entry链的尾部
jdk8 顺序不变
注意: 当容量为2^n时,h & (length - 1) == h % length” . 按位运算特别快,非2^n时候,数据不能均匀分布在数组中
remove方法
1 | //删除key对应的键值对 |
1 | //参数matchValue为true表明只有key在HashMap中对应值为value时才删除; 为false表示强制删除; |
SynchronizedMap()方法
创建SynchronizedMap封装类,实现map接口,对map方法进行加锁重写,调用原方法
Hashtable
1 | public class Hashtable<K,V> |
数据结构
- 不支持空键空值
- 初始长度 11
- 默认负载因子 0.75
- 线程安全 方法synchronize 修饰
- 数组最大长度 Integer.MAX_VALUE - 8 ,防止OOM
源码分析
- get()
1 | public synchronized V get(Object key) { |
- rehash()扩容
1 | protected void rehash() { |
- put()
1 | public synchronized V put(K key, V value) { |
- 迭代遍历
初始化expectedModCount = modCount; next()判断不相等抛出异常ConcurrentModificationException
LinkedHashMap
1 | public class LinkedHashMap<K,V> |
数据结构
- Entry节点结构
1 | class Entry<K,V> extends HashMap.Node<K,V> { |
有序性:提供保持插入顺序的
(accessOrder = false)LinkedHashMap 和 保持访问顺序的LinkedHashMap,LinkedHashMap的默认实现是按插入顺序排序的resize()
jdk1.6 通过双向链表进行遍历旧数据
- get() put() 会更将节点置为双向链表尾部
TreeMap
1 | public class TreeMap<K,V> |
树
- 树: 可以有多个子节点,顶部只有一个节点,顶部小,底部大
. 二叉树: 每个节点最多有两个子节点- 叶子节点: 没有子节点的节点
- 层: 根节点到该节点经过多少代
- 树变二叉树
树变二叉树的规则:每个结点的左指针指向它的第一个孩子结点。右指针指向它在树中的相邻兄弟结点。
也即:左孩子右兄弟。
根没有兄弟,所以转换以后的树没有右子树。
具体操作:
1. 在兄弟之间连线
2. 对每一个结点,只保持它与第一个子结点(长子)的连线,与其他子结点的连线全部抹去。
3. 以树根为轴心,顺时针旋转45度。
- 二叉树变树
二叉树变树的规则:是树变二叉树的逆过程。问:二叉树可以变成各种各样的树,为何这里只是唯一一种树形?这里只是假设这个二叉树是由上面的变换算法得来,那么过程可逆。所以对于有右子树的二叉树树形,是不能用这种办法化为树的
具体操作:
1. 加线。如果某个结点有左孩子,那么把这个左孩子的右孩子,右孩子的右孩子,一直右下去,全部连接到这个结点。这个对应树变二叉树算法中的抹掉与长子以外的结点的连线,现在要找回自己的全部儿子。
2. 去线。删除树中所有结点与这些右孩子的连线。找回了自己的儿子,不容许别人还和它们有瓜葛。
3. 层次调整。
- 平衡二叉树: 它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。也就是说该二叉树的任何一个等等子节点,其左右子树的高度都相近。
红黑树
特性:
1、每个节点都只能是红色或者黑色
2、根节点是黑色
3、每个叶节点(NIL节点,空节点)是黑色的。
4、如果一个结点是红的,则它两个子节点都是黑的。也就是说在一条路径上不能出现相邻的两个红色结点。
5、从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
- 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长
- 检索效率O(log n)
- 左旋

1 | LEFT-ROTATE(T, x) |
- 右旋

1 | RIGHT-ROTATE(T, y) |
TreeMap
数据结构
- TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
- TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
- TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
- TreeMap 实现了Cloneable接口,意味着它能被克隆。
- TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
- TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
- TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
- TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
- 节点信息
1 | static final class Entry<K,V> implements Map.Entry<K,V> { |
源码分析
- firstEntry() 和 getFirstEntry()
都是用于获取第一个节点。
但是,firstEntry() 是对外接口, 防止用户修改返回的Entry; getFirstEntry() 是内部接口
firstEntry()
返回exportEntry(getFirstEntry())
exportEntry: 新建一个AbstractMap.SimpleImmutableEntry类型的对象,并返回
- value()函数
1 | public Collection<V> values() { |
1 | class Values extends AbstractCollection<V> |
Values类就是一个集合。而 AbstractCollection 实现了除 size() 和 iterator() 之外的其它函数,因此只需要在Values类中实现这两个函数即可。
iterator() 则返回一个迭代器,用于遍历Values
1 | public Iterator<V> iterator() { |
iterator() 是通过ValueIterator() 返回迭代器的,ValueIterator是一个类,它的主要实现应该在它的父类PrivateEntryIterator中
PrivateEntryIterator是一个抽象类,它的实现很简单,只实现了Iterator的remove()和hasNext()接口,没有实现next()接口。
而我们在ValueIterator中已经实现的next()接口