JUC lock概述
1. 前言
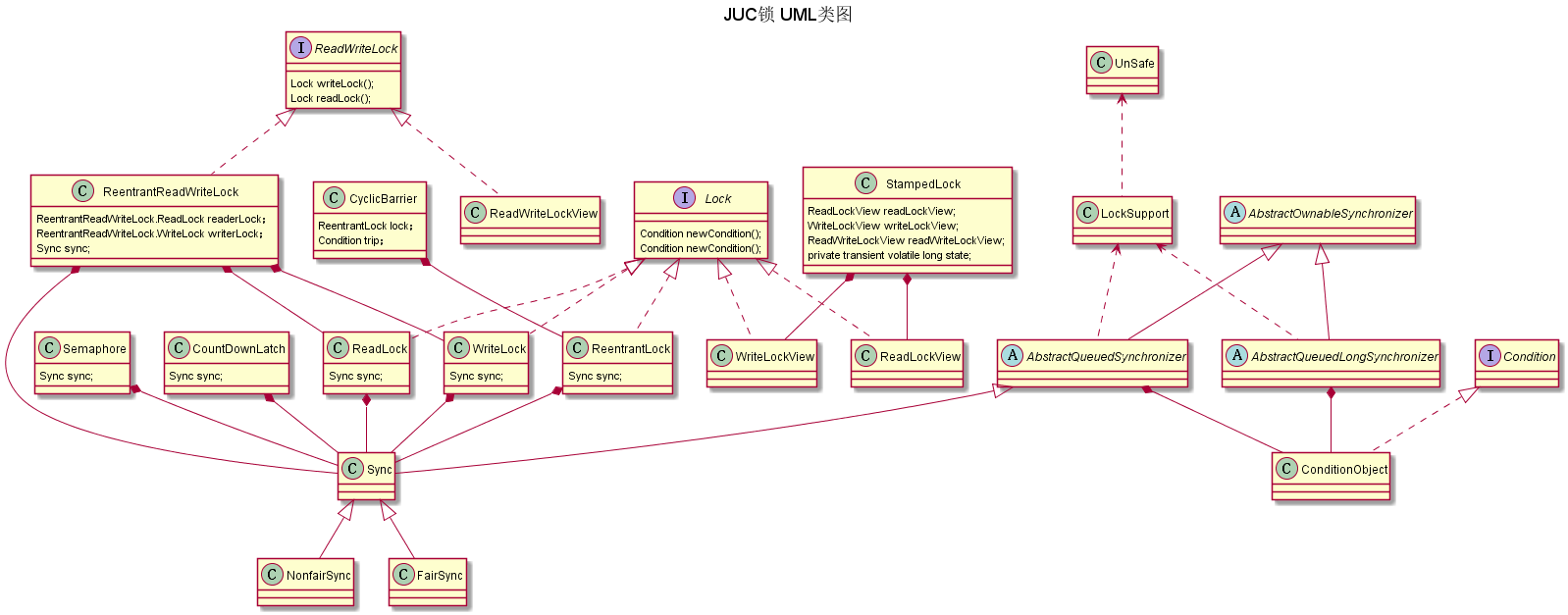
JUC包中的锁,包括:Lock接口,Condition条件,ReadWriteLock接口,LockSupport阻塞原语,AbstractOwnableSynchronizer/AbstractQueuedSynchronizer/AbstractQueuedLongSynchronizer三个抽象类,ReentrantLock独占锁,读写锁ReentrantReadWriteLock,jdk1.8新增StampedLock。CountDownLatch,CyclicBarrier和Semaphore也是通过AQS来实现的,也将它们归纳到锁的框架中进行介绍。
框架图如下:
2. 源码解析
2.1 Lock接口
- 提供比synchronized更广泛的锁操作:更灵活的结构,可能有多种属性,支持多个相关联的条件
- Lock允许获取和释放锁在不同范围,允许任意顺序获取和释放多个锁
- Lock 提供非阻塞方法获取锁
tryLock(),尝试获取可中断的锁lockInterruptibly(),以及可设置获取锁超时tryLock(long, TimeUnit) - Lock 接口支持那些语义不同(重入、公平等)的锁规则。所谓语义不同,是指锁可是有”公平机制的锁”、”非公平机制的锁”、”可重入的锁”等等。”公平机制”是指”不同线程获取锁的机制是公平的”,而”非公平机制”则是指”不同线程获取锁的机制是非公平的”,”可重入的锁”是指同一个锁能够被一个线程多次获取。
1 | public interface Lock { |
2.2 Condition接口
Condition需要和Lock联合使用,它的作用是代替Object监视器方法,可以通过await(),signal()来休眠/唤醒线程。 Condition 接口描述了可能会与锁有关联的条件变量。这些变量在用法上与使用 Object.wait 访问的隐式监视器类似,但提供了更强大的功能。需要特别指出的是,单个 Lock 可能与多个 Condition 对象关联。
1 | public interface Condition { |
2.3 ReadWriteLock接口
读写锁与一般的互斥锁不同,它分为读锁和写锁,在同一时间里,可以有多个线程获取读锁来进行共享资源的访问。如果此时有线程获取了写锁,那么读锁的线程将等待,直到写锁释放掉,才能进行共享资源访问。简单来说就是读锁与写锁互斥。
读写锁比互斥锁允许对于共享数据更大程度的并发。每次只能有一个写线程,但是同时可以有多个线程并发地读数据。ReadWriteLock适用于读多写少的并发情况。
1 | public interface ReadWriteLock { |
2.4 LockSupport
LockSupport 基本线程阻塞原语
LockSupport中的park() 和 unpark() 分别对应Thread类中的suspend()和resume(),但不会引发死锁问题
2.5 AbstractOwnableSynchronizer
帮助记录当前保持独占同步的线程的抽象类,实现类为AbstractQueuedSynchronizer(即AQS) 和 AbstractQueuedLongSynchronizer。
AQS可用来定义锁以及依赖于排队阻塞线程的其他同步器;ReentrantLock,ReentrantReadWriteLock,CountDownLatch,CyclicBarrier和Semaphore等这些类都是基于AQS类实现的。
AbstractQueuedLongSynchronizer 类提供相同的功能但扩展了对同步状态的 64 位的支持。
2. 6 ReentrantLock
ReentrantLock是独占锁,即同一个时间点只能被一个线程锁获取到的锁 。ReentrantLock分为“公平锁”和“非公平锁”。它们的区别体现在获取锁的机制上是否公平。
ReentrantLock的UML类图如下:

2.7 ReentrantReadWriteLock
ReentrantReadWriteLock是读写锁接口ReadWriteLock的实现类,它包括子类ReadLock和WriteLock。ReadLock是共享锁,而WriteLock是独占锁。
ReentrantReadWriteLock的UML类图如下:

2.8 StampedLock
StampedLock是对读写锁的改进,在读多写少的情况下,可能造成写线程遭遇饥饿问题。StampedLock控制锁有三种模式(写,读,乐观读),一个StampedLock状态是由版本和模式两个部分组成。UML类图如下:

2.9 CountDownLatch
CountDownLatch是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。
UML类图如下:

2.10 CyclicBarrier
CyclicBarrier是一个同步辅助类,允许一组线程互相等待,直到到达某个公共屏障点。
UML类图如下:

2.11 Semaphore
Semaphore是一个计数信号量,它的本质是一个共享锁。
线程可以通过调用acquire()来获取信号量的许可;当信号量中有可用的许可时,线程能获取该许可;否则线程必须等待,直到有可用的许可为止。 线程可以通过release()来释放它所持有的信号量许可。
UML类图如下: